Other Parts of This Series:

Database Internals (Photo Credit: LinkedIn Image)
Database internals refer to how a database system works behind the scenes. Like how it stores data in memory and on disk, how it manages updates and deletions, and how it retrieves data efficiently. So as you can imagine, it is a huge topic and a vast area to discuss. But before starting, I want to set the expectation level. In this article, I just touch on the concepts in a summary style and do not go into details to keep it short. If you feel really interested, then you can search each topic and learn the details. Also, you can deep dive into the further learning section given at the end of this article. So let’s get started…
DBMS Architecture Types
A DBMS (Database Management System) architecture describes how different components interact to store, process, and retrieve data. The architecture determines performance, scalability, and fault tolerance. They are:
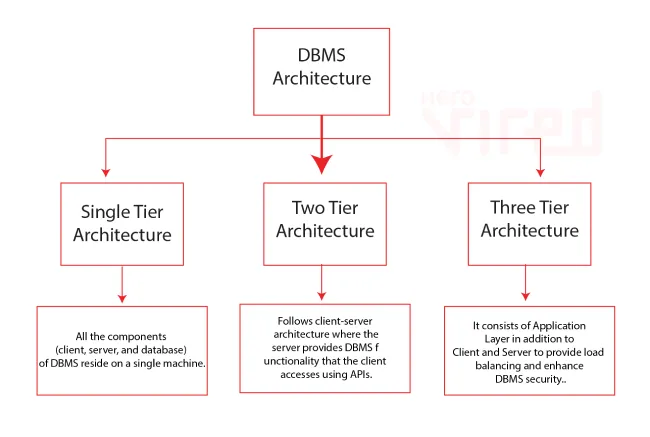
DBMS Architecture Types
- Single-Tier (Monolithic): The application and database are in the same system (e.g., SQLite). Suitable for lightweight applications.
- Two-Tier (Client-Server): The database runs on a server, and applications communicate with it via SQL queries (e.g., MySQL, PostgreSQL).
- Three-Tier (Middleware Architecture): An API or middleware layer sits between the client and the database (common in web applications).
Primary Components of DBMS
A DBMS consists of some primary components which come together to perform the database operation effectively. Like a component is responsible for request and its network communication and other is responsible for optimize this request for next step. Also a component is plan a optimize execution plan and other handles the data store finally.
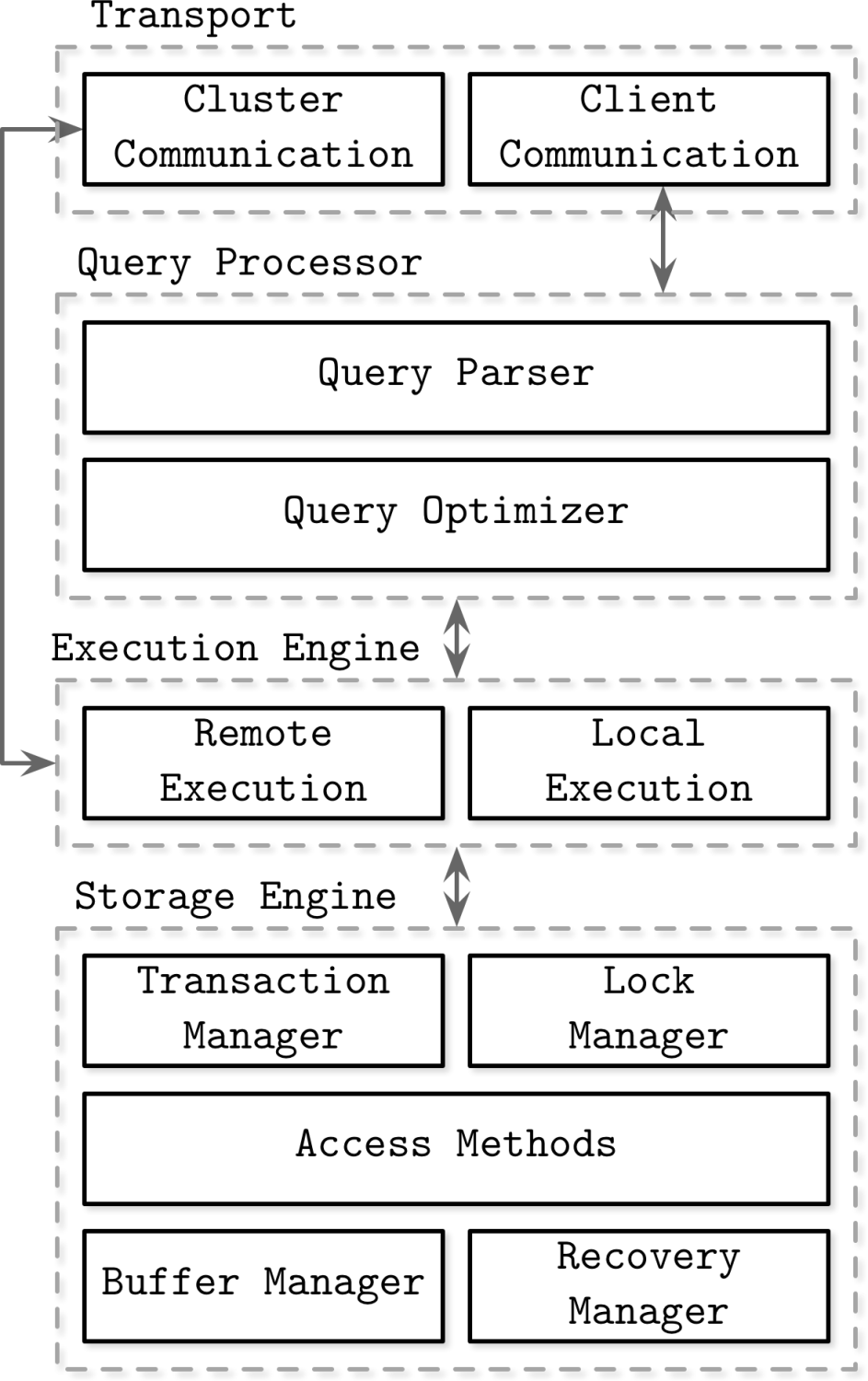
Each sub-part perform some specific job
1. Transport Subsystem
- Handles client requests over the network. Also manages network communication.
- Uses TCP/IP, HTTP, gRPC protocols to communicate with the DBMS.
- Provides authentication & authorization mechanisms.
2. Query Processor
- Breaks down SQL queries into an optimized execution plan.
- Sub components: Parser: Validates SQL syntax and semantics. Optimizer: Chooses the most efficient way to execute the query based on indexes and statistics. Execution Planner: Translates the query into a sequence of operations.
3. Execution Engine
- Executes queries using a query plan.
- Fetches and processes data from the storage engine.
- Optimizes query execution using parallelism, caching, and indexing.
4. Storage Engine
- Manages data structures, indexing, and access methods.
- Can be row-based (MySQL InnoDB, PostgreSQL) or column-based (Apache Parquet, Apache ORC).
- Uses B-Trees, LSM Trees, or Heap files for storage.
- Data is divided into smaller chunks and stored in a way that makes it easy to find, update, and delete. Implements buffer pools, indexing, and data compression.
- Uses WAL (Write-Ahead Logging) for durability.
Major Concepts to Handle: Buffering, Immutability, Ordering
The underlying structure and mechanism of storage engine are making to deal with the following concepts. Based on the data structure and implementation the following things vary a lot. But it obvious for any storage engine to deal with them.
1. Buffering (Caching for Performance)
- Uses memory (RAM) to temporarily store data pages before writing them to disk.
- Buffer Pool: Stores frequently accessed data to reduce disk I/O.
- Uses different Cache Eviction Algorithm to evict old pages.
2. Immutability (Append-Only Writes)
- Some databases use immutable (unchangeable) storage.
- Instead of modifying data in place, new versions are created (used in LSM Trees).
- This reduces write amplification and improves performance.
3. Ordering (Maintaining Sorted Data)
- Databases use B-Trees, LSM Trees, and SSTables to store ordered data.
- Helps in range queries, sorting, and indexing.
Underlying Data Structures for Data Storage
Its very helpful to know the data structure that many different type of DBMS used. Because the underlying data structure and its implementation has a direct impact on database performance and memory size. Also understanding those data structure helps you to easily visualize the database.
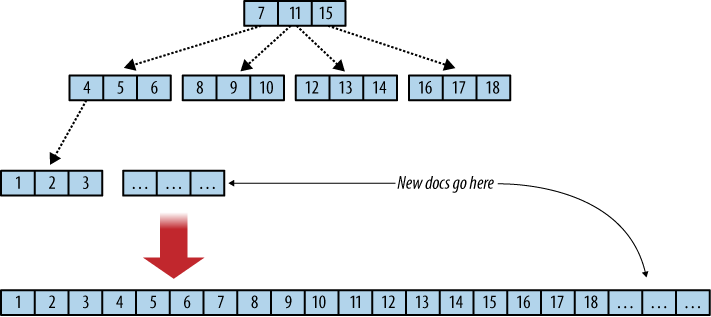
B-Tree
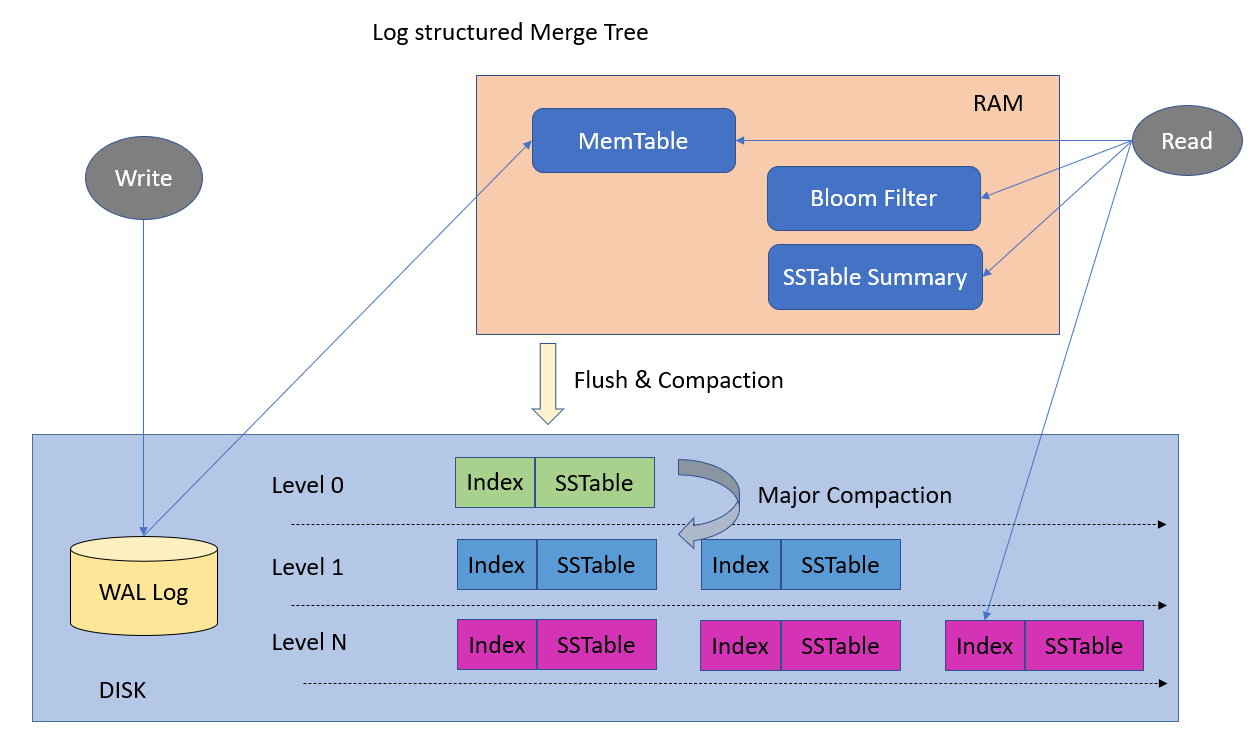
LSM Tree
1. Heap Files (Unordered Storage)
- Stores data without any particular order.
- Used in NoSQL databases like MongoDB.
2. Hash Indexing (Unordered Storage)
- Used for key-value lookups but not range queries.
- Used in Key-value pair databases like DynamoDB.
3. B-Trees (Balanced Tree Indexing)
- Used in MySQL, PostgreSQL, Oracle.
- Keeps data sorted and enables fast lookup, insert, and delete operations.
4. LSM Trees (Log-Structured Merge Trees)
- Used in Cassandra, RocksDB, LevelDB.
- Optimized for fast writes, but requires compaction to merge files.
5. Columnar Storage
- Used in analytical databases (Apache Parquet, Apache ORC).
- Improves performance for data analytics queries.
Page / Tree Split and Merge Mechanism
Data with its meta data information in a database engine is called or stored as page in disk. Page can be visualize as a node of a tree like data structure. Split and merge techniques helps utilize the memory and organizing nodes effectively.
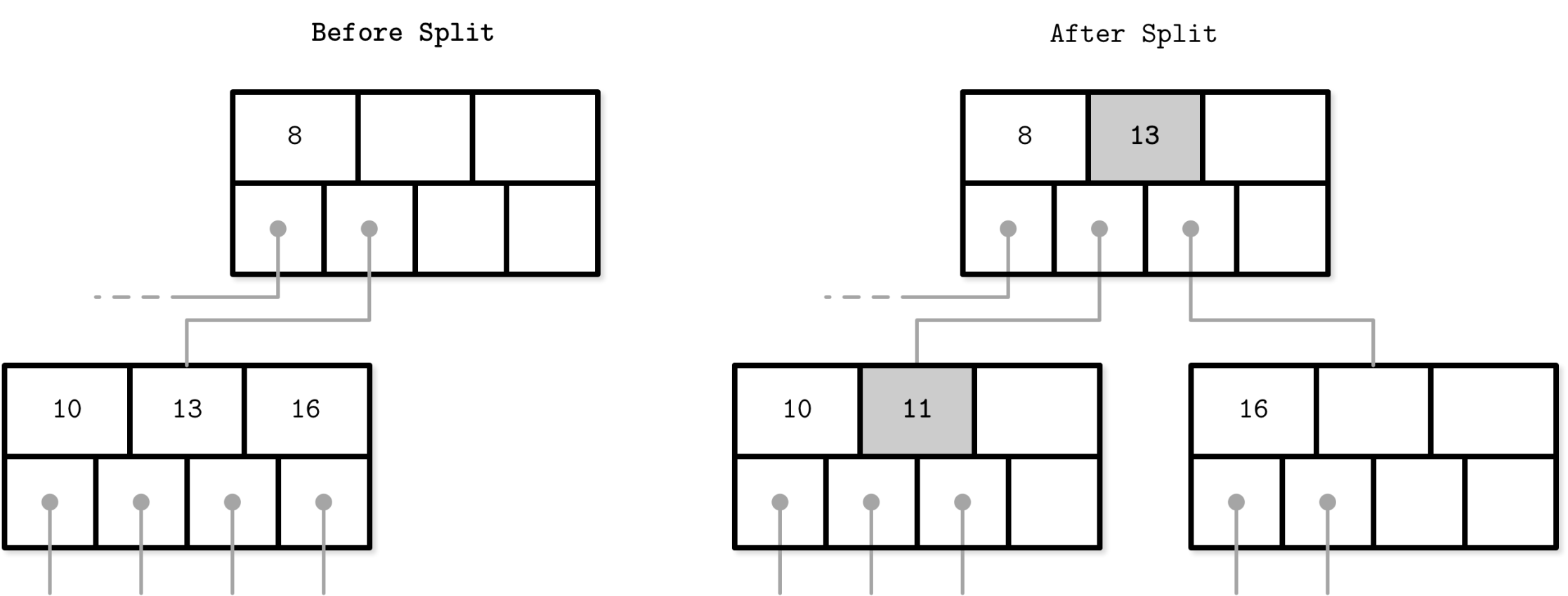
B-tree split
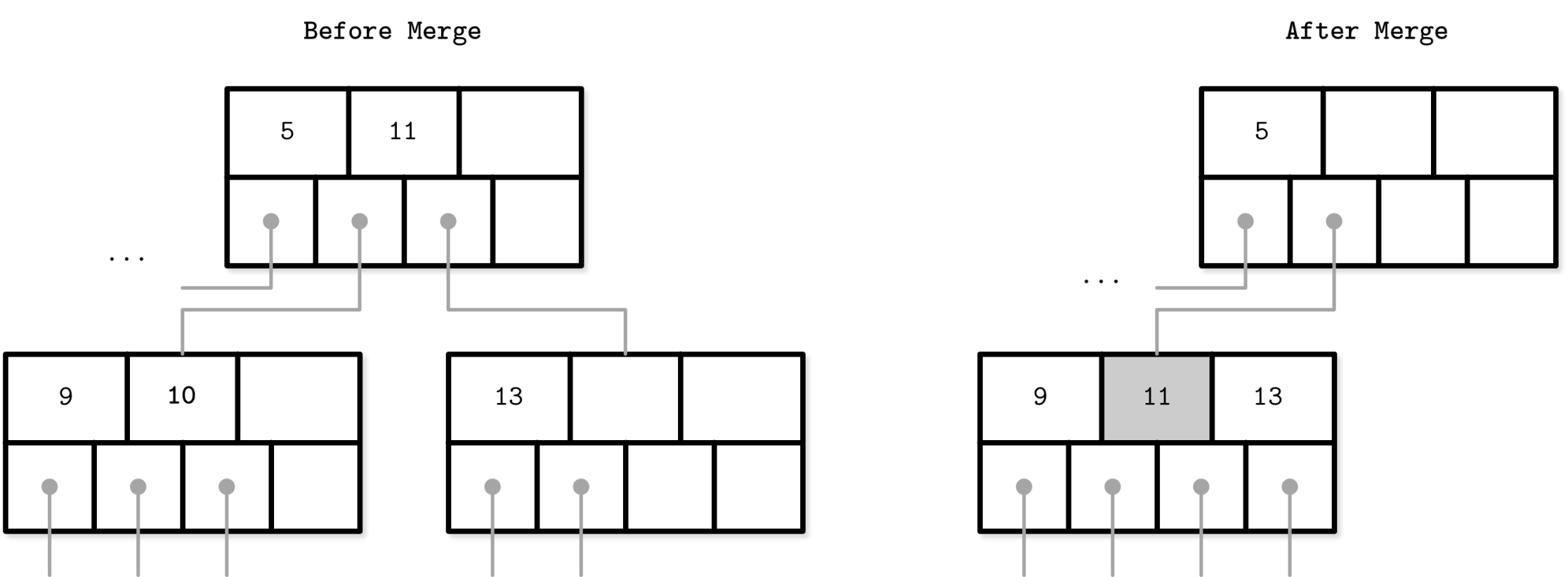
B-tree merge
1. Page Split (B-Trees & LSM Trees)
- When a page reaches its size limit, it splits into two nodes.
- The median key moves up to the parent node, ensuring balance.
2. Page Merge (B-Trees)
- If a node has too few entries due to deletions, it merges with a sibling node.
- Prevents under-utilization of storage.
3. LSM Tree Compaction
- Periodically merges small SSTables into larger ones to optimize performance.
- Reduces fragmentation.
Fragmentation and Defragmentation
Fragmentation means data beings scattered so underutilize, and defragmentation means utilize those again by reclaim space.
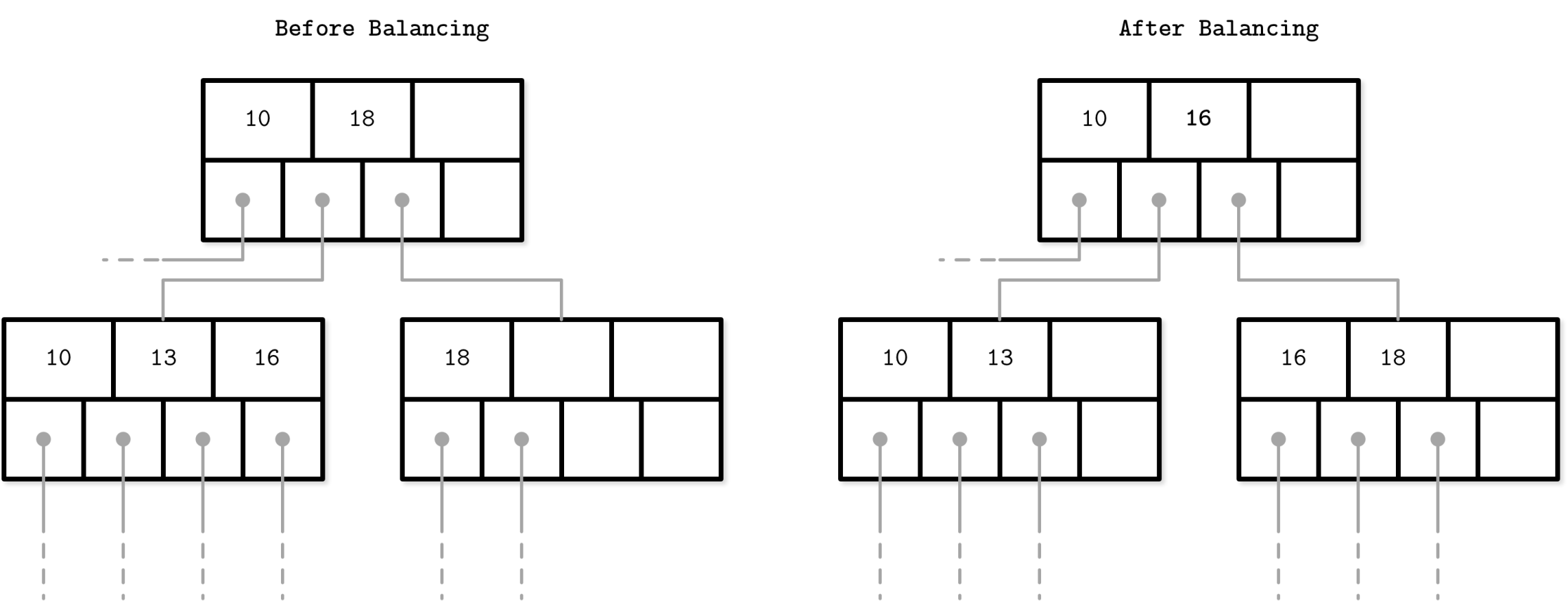
Balancing
1. Fragmentation
- Happens when data gets scattered across multiple pages due to updates/deletes.
- Increases disk I/O latency.
2. Defragmentation
- PostgreSQL’s VACUUM reorganizes storage to reclaim space.
- MySQL’s OPTIMIZE TABLE defragments tables.
Transaction Management, Transaction Buffering, and Locking
Handling transaction and restrict duplication of data writes are one of the important aspects of DBMS. So its need extra care.
1. ACID Transactions
- Atomicity: Either all operations succeed or none.
- Consistency: Database moves from one valid state to another.
- Isolation: Transactions don’t interfere with each other.
- Durability: Once committed, changes persist permanently.
2. Transaction Buffering
- Transactions are first written to a memory buffer before disk.
- Uses Write-Ahead Logging (WAL) for durability.
3. Locking in Concurrency Control
- Shared Locks: Multiple transactions can read but not write.
- Exclusive Locks: Only one transaction can access the data.
- Deadlocks are resolved using wait-for graphs.
Cache Concept in Databases
For increasing the database performance effective caching is essential.
- Buffer Pool: Stores frequently accessed data pages in memory.
- Query Cache: Caches results of repeated queries.
- Write-Back Cache: Delays disk writes for efficiency.
Locks and Latches Concept
For maintaining the atomicity, consistency and handling concurrency locking and latches technique is must have item.
- Locks protect data consistency (row/table locks).
- Latches protect internal database structures (index pages).
- Latches are lighter and faster than locks.
Log-Structured Storage and LSM Tree
Write heavy system uses this data structure.
- Log-Structured Storage: Appends new writes sequentially.
- LSM Tree: Writes to memory (memtable), then flushes to disk (SSTables).
- Uses compaction to optimize read performance.
Sorted String Table (SSTable)
It is the backbone for log structured storage and LSM tree.
- Immutable files storing sorted key-value pairs.
- Used in LSM Trees for fast lookups.
- Optimized for sequential writes.
Other Used DSA in DBMS
1. SkipList
- Alternative to B-Trees for in-memory indexing.
2. Bloom Filter
- Probabilistic data structure that speeds up key existence checks.
3. RAFT & PAXOS
- Consensus algorithms for leader election and consistency in distributed databases.
Distributed Transaction Management
Distributed system is not so straight forward like single instance solution. There are many factor needs to be considered while working with distributed system. So designing and working with distributed database needs extra care.
1. Two-Phase Commit (2PC)
- Phase 1: Prepare - Nodes prepare for commit.
- Phase 2: Commit - If all nodes agree, transaction commits.
2. Three-Phase Commit (3PC)
- Adds an extra pre-commit phase for fault tolerance.
3. Distributed ACID Transactions
- Uses global timestamps, locks, and replication for consistency.
4. Eventual Consistency (NoSQL)
- Data propagates asynchronously, ensuring availability over consistency.
Summary:
A DBMS manages data using components like the query processor, execution engine, and storage engine. It optimizes performance through buffering (caching data in memory), immutability (append-only writes), and ordering (B-Trees, LSM Trees for fast lookups). Data structures like B-Trees (indexing) and LSM Trees (fast writes) play a key role, while transactions ensure ACID compliance using WAL (Write-Ahead Logging). Locks/latches manage concurrency, and distributed transactions use 2PC for consistency, while NoSQL databases rely on eventual consistency. Algorithms like Bloom Filters (fast key lookups), RAFT & PAXOS (distributed consensus) enhance efficiency.