Other Parts of This Series:
- Part 9: Tale of Software Architect(ure): Part 9 (MVC Architecture Pattern)
- Part 11: Tale of Software Architect(ure): Part 11 (Microkernel Architecture)

Pipe-Filter Architecture (Photo Credit: LinkedIn Image)
In this series, we try to explore the software architecture in a nutshell. We will try to learn the different aspects of software architecture and software architects one by one. In this part, we try to explore the pipe-filter software architecture pattern.
So let’s get started…
Story
Once upon a time, in a village, there was a great river called the River of Knowledge. This river flowed from the highest mountains, carrying messages, stories, and wisdom to the people of the land. But the river was wild and full of all sorts of information, some useful, some unnecessary, and some even misleading.
The most wise man of the village suggest a way to filter and organize the river’s knowledge, so that only the most important and relevant information reached to people. To solve this problem, village people decided to hire, a group of clever engineers who were known for their ability to transform chaos into order. So the clever engineers perform separate filtering of these knowledge and combinedly generate the expected results.
Pipe Filter Architecture:
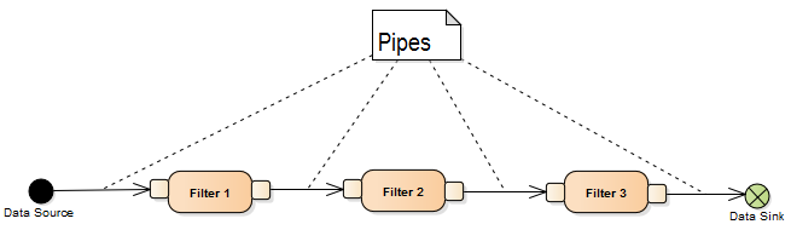
Pipe-Filter Architecture (Photo Credit: modernescpp)
The Pipe and Filter architecture also known as Pipeline architecture is a design pattern where a task is divided into several sequential processing steps, each of which is called a filter. These filters process data and pass the output to the next step via a pipe. Each filter operates independently, transforming input data from the previous stage before sending it along the pipe.
Key Components:
- Filter: A filter performs a specific operation, transforming input data into output. Filters are independent units and do not rely on each other’s internal processes.
- Pipe: A pipe transfers data from one filter to the next. It defines the flow of data through the system.
- Data stream: Data moves through pipes from one filter to another, allowing continuous flow and transformation.
Context:
In real world there has some systems that process a stream of data in a series of sequential or parallel stages. Each stage performs a specific transformation or operation on the data. So we need a suitable architecture for these types of applications where:
- Data flows continuously or in chunks (e.g. logs, streams, files).
- The process can be broken down into smaller, independent steps.
- Flexibility and reusability of these independent components are important.
- Scalability is needed, especially if the data flow needs to be handled by distributed or parallel systems.
Problem:
The problem arises when you need to process large or continuous streams of data in multiple stages. Without a structured architecture, such systems can become tightly coupled, making them hard to maintain, extend, or scale. Some of the key challenges include:
- Tight Coupling: When the data processing stages are not clearly separated, it becomes difficult to modify or maintain individual steps.
- Low Reusability: Without clear separation, individual processing steps (like filtering, sorting, etc.) cannot easily be reused in other contexts.
- Limited Scalability: In monolithic data processing workflows, it’s hard to scale the system for larger datasets or parallelize stages for better performance.
- Maintenance Complexity: A system where steps are interdependent and intertwined is difficult to update, extend, or debug.
Solution:
The Pipe and Filter architecture addresses these issues by breaking the data processing task into a series of independent, well-defined filters, each of which performs a single transformation on the data. These filters are connected by pipes that allow data to flow from one filter to the next.
This structure solves the problem in several ways:
- Modular Design: Each filter is an independent unit, making the system easier to maintain. If a filter needs to be modified, replaced, or removed, other filters remain unaffected.
- Reusability: Since filters are designed to be independent, they can be reused in different pipelines or systems with minimal adjustments. For example, a filter designed to sort data can be used in various pipelines, regardless of the specific data being processed.
- Scalability: Filters can be run in parallel, allowing the system to process large datasets more efficiently. For example, multiple filters can be executed concurrently in a distributed environment to increase throughput.
- Flexibility: New filters can be easily added, and the sequence of filters can be changed or rearranged to create new pipelines without affecting existing components.
- Ease of Maintenance and Testing: Since each filter is a self-contained unit with well-defined input and output, it becomes easier to isolate issues during debugging. Filters can also be individually tested.
Example Solution:
Let’s say you are building a log processing system that needs to:
- Read log files.
- Extract lines containing error messages.
- Sort them by timestamp.
- Remove duplicates.
- Output the cleaned log.
Using the Pipe and Filter architecture:
- You would create independent filters for each of these tasks: one for reading logs, one for extracting errors, one for sorting, and one for removing duplicates.
- These filters would be connected by pipes to pass the data from one stage to the next.
- Each filter can be independently developed, tested, and reused in different log processing pipelines if necessary.
Pseudocode:
| |
Summary:
The Pipe and Filter architecture is very suitable for stage by stage data processing application. Because we can easily create independent filter and join them with pipes. Also for this type of architectural application Functional Programming is a very handy choice.
This architecture brings modularity, reusability, scalability and flexibility out of the box.